The Alteryx engine is known for being fast. I would like to think that the processing engine is as fast or faster than any other data engine out there. I learned how to program on a computer with 16 KB of memory and a 2 MHz 8 bit CPU. Learning how to program in an environment like that forces you to learn how to count bits and clock cycles. Taking that mentality and applying it to a modern computer leads to very quick processing.
The difficulty though is that Alteryx is limited to the speed it can read & write data from where it is stored. Having a super fast data processing engine doesn’t help if you have to pull a terabyte of data from a data warehouse only to find a subset of it and produce a report. It doesn’t help to be fast if it is slow to get the needed data.
In order to address this, it would be nice to allow some of the processing to be in the database where the data resides. That way native indexes and other structures could be used to speed up the reduction of data sizes that could then be brought in to Alteryx for deeper processing. While some of this can be done now, it typically requires the user to know SQL code and tools like the Dynamic Input and it has some serious limitations.
At Inspire 14 George Mathew talked about in database processing. He was very clear to point out that it was only a research project. The tools (which he called meta tools) that he and Damian demo’d were all macros using the R engine to interface with a database. While a fantastic proof of concept, it had some limitations from being written in R and using macros that would be difficult to overcome.
Before going on, I feel the need to point out that everything I am talking about below is NOT currently part of Alteryx. I am showing a research project that is very much a work in progress.
Now that the stage is set, let me introduce project LockIn. In July I set off to create the foundation of a new set of tools within Alteryx for processing in database. I turned off email and IM for a while (locking myself in, if you will) and came out a little while later with a prototype for a new tool category in Alteryx. The idea is that you can author a process to run inside of a database engine with the same easy user interface that you author a workflow inside of Alteryx. Furthermore you can mix in-database processing and in-Alteryx processing within the same module. Once again please note: this is not part of the upcoming Alteryx 9.1 release – the rest of the team is going to start working on turning this into a real product after the 9.1 release. Without further ado, here is a screenshot of the LockIn tools in Alteryx:
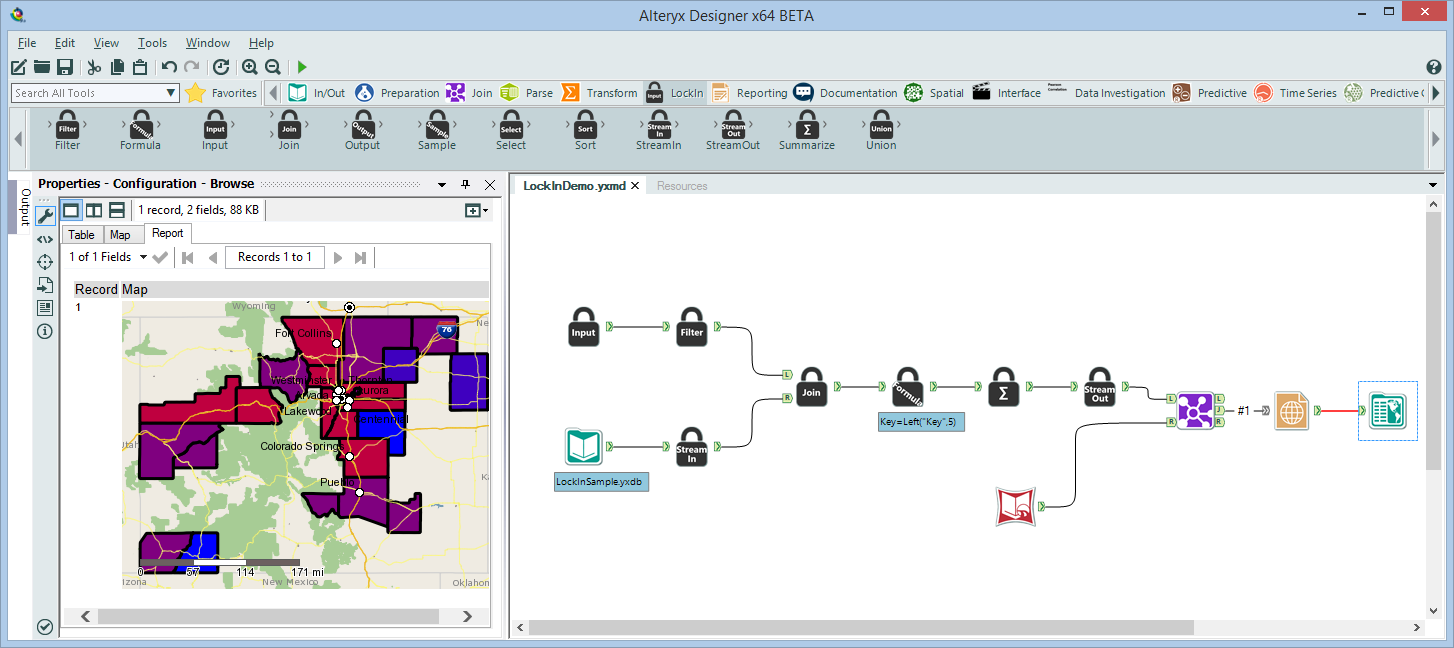
There is a lot going on in this small module. 1st – you can see the LockIn tool category (which will obviously be called something else when it releases.) Most of the tools from the favorites have been replicated here, with as similar a UI as possible to the original tools (see below screenshots of a few LockIn tool’s UI). There are 2 additional tools, Stream In and Stream Out. The demo module takes a table that is currently residing in-database and joins to a table coming from Alteryx. The Stream In tool allows data to stream into the database from Alteryx. Sometimes it is better to take a small amount data and push it into the database then pull a large amount out. In this example I have a large table in the database and a small table outside to join with it.
Like a regular Alteryx processes you can combine filters and summarizes and other such tools to create a more complicated process. No SQL required! At the end of the LockIn process you have 2 choices: a LockIn Output tool, or a Stream Out tool. The output tool creates a table in the database without the data ever coming into the Alteryx engine. The Stream Out tool allows you to take the results of the in-database process and bring them in to Alteryx. In this module I stream the data out and then combine the results with spatial objects and create a map. You could just as easily take the results and put them into a Tableau Data Extract or anything else that Alteryx supports.
Once again, this is a work in progress – I hope that this will be in Alteryx 9.5 working within a few different database platforms. While it will be a single set of tools no matter which database they are running within, the developers at Alteryx will need to explicitly support each and every platform in code. One of the next steps is obviously going to be to support the R engine (on platforms that support it) so that predictive tools can be used in the same way inside of the database engine.
I expect that there will be a lot of changes by the time this turns into a product – this is just the continuation of the research project that George announced at Inspire. It is also not too late for customer input – if you have any suggestions feel free to contact the product management team at Alteryx or me directly (ned [at] inspiringingenuity.net). As always, we would love to hear from you.
Thanks for reading,
Ned.
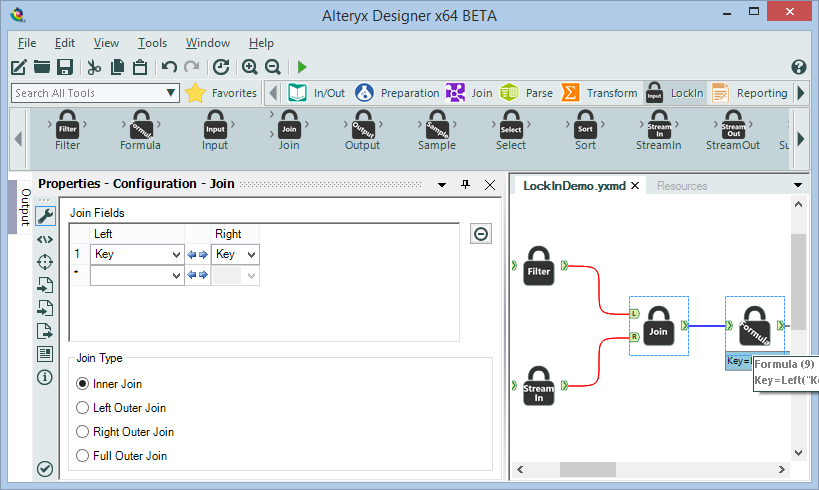
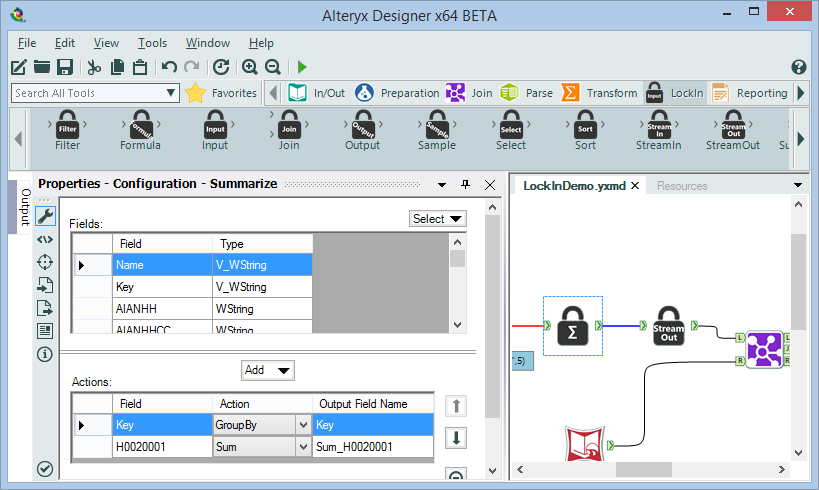
A few more LockIn tool UIs – looking very similar to other Alteryx tools:

August 16, 2014 at 7:37 pm
yes yes and yes this will be awesome when we run on so hug data sets. We are constantly using alteryx to smash in 10 small tables and going back to run in database processes.
If we were able to stream in regression models built in the first half of the module to in database that would be cool. KXEN has a really sweet feature that does this where you have a complex model like non parametric ridge regression it will output the model in SQL or SAS code.
something like if we could stream in the model and have the score tool pre-script the product of the coeff. and the variable in database that would save killer time for us modeling folks.
Thanks
G
August 18, 2014 at 10:35 am
Thanks for your comment Garry. I’m JC with Alteryx product management. I’d like to make sure I understand your use case in details. If interested, please feel free to send your contact details to jc.raveneau [at] alteryx.com so I can get back to you.
Thanks!
JC
August 18, 2014 at 9:15 am
Just shared this with the Alteryx Carolina Users Group – going to make some folks very happy.
August 26, 2014 at 12:04 pm
Ned – this is a game-changer in advanced analytics. Create in-database memory processing will be huge as customers analyze much more data, and increasingly migrate to big data platforms (Hadoop, etc) . Great to see Alteryx moving in this direction.